Demonstration of ECHO generating a radiology report from a chest X-ray input.
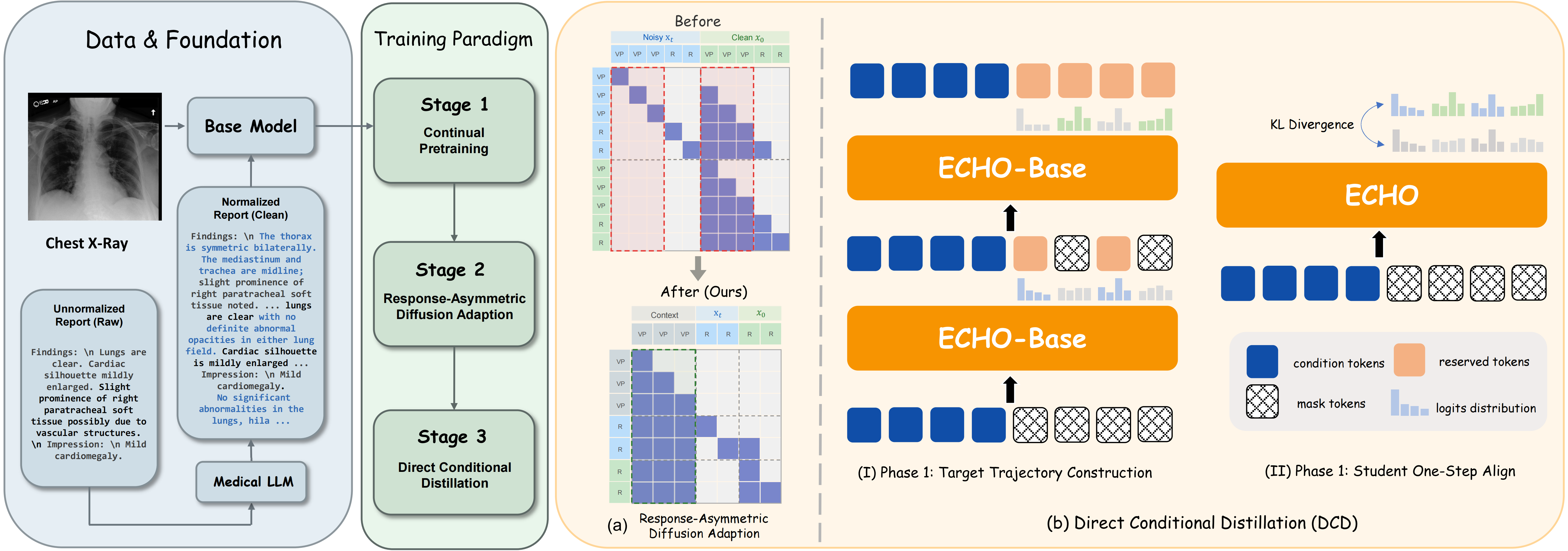
ECHO is a discrete diffusion vision–language model for automated chest X-ray report generation. Existing diffusion language models face an inherent quality–speed trade-off, where generating coherent outputs requires multiple denoising steps that substantially increase inference latency. ECHO overcomes this limitation by introducing non-factorized distillation targets constructed from the teacher's on-policy denoising trajectory, enabling coherent one-step-per-block inference that prior distillation methods could not achieve. A response-asymmetric adaptation strategy further reduces the training cost of AR-to-diffusion conversion by eliminating redundant processing of long vision token contexts. On three public CXR benchmarks, ECHO consistently outperforms autoregressive and diffusion-based state-of-the-art models, improving RaTEScore and SemScore by 64.33% and 60.58% respectively over AR baselines, while achieving up to an 8× inference speedup with marginal quality degradation.
Discrete diffusion language models approximate the joint token distribution through token factorization, treating each position as conditionally independent. This approximation ignores inter-token dependencies, requiring multi-step remasking to progressively recover output coherence. Each additional denoising step, however, incurs an extra model forward pass, increasing inference latency and creating a fundamental quality–speed dilemma. ECHO resolves this through Direct Conditional Distillation (DCD), which constructs non-factorized supervision from the teacher's on-policy multi-step trajectories, enabling the student to capture joint token dependencies in a single forward pass per block — achieving multi-step quality at single-step speed.
ECHO is built through three successive training stages, from a domain-specialized autoregressive model to a multi-step block diffusion backbone, and finally to the distilled one-step-per-block model. Response-Asymmetric Diffusion (RAD) adapts the autoregressive model into a block diffusion model by duplicating only the response portion of each training sequence, which eliminates the redundant processing of long vision token contexts imposed by prior two-stage conversion methods. Direct Conditional Distillation (DCD) then distills this multi-step teacher into a single-step student by constructing joint, non-factorized supervision targets from the teacher's confidence-heuristic remasking trajectory, allowing the student to capture inter-token dependencies that single-step decoding would otherwise lose.
🏥 State-of-the-Art CXR Report Generation. ECHO consistently outperforms both autoregressive and diffusion-based state-of-the-art models on clinical fidelity metrics, with improvements of 64.33% on RaTEScore and 60.58% on SemScore over strong AR baselines, including models larger in size.
⚡ Up to 8× Inference Speedup. ECHO achieves up to an 8× decoding speedup over multi-step diffusion baselines with only marginal quality degradation, offering a more favorable quality–speed trade-off than all existing distillation methods across block size configurations.
🧩 Training-Efficient AR-to-Diffusion Adaptation. By duplicating only the response tokens rather than the full sequence during adaptation, ECHO reduces training FLOPs by 72.3% relative to prior two-stage conversion methods, making the AR-to-diffusion conversion substantially more practical at the scale of high-resolution medical images.
ECHO is comprehensively evaluated on multiple public CXR benchmarks against a wide range of baselines. On clinical fidelity metrics, ECHO outperforms MedGemma-27B, the current open-source state-of-the-art medical VLM, by 17–40%. Among diffusion-based methods, ECHO also achieves superior quality–speed trade-offs, reaching up to 274 tokens per second and a throughput of 8 tokens per forward pass with only marginal quality degradation relative to the multi-step teacher.
@article{chen2026echoefficientchestxray,
title={ECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion},
author={Lifeng Chen and Tianqi You and Hao Liu and Zhimin Bao and Jile Jiao and Xiao Han and Zhicai Ou and Tao Sun and Xiaofeng Mou and Xiaojie Jin and Yi Xu},
year={2026},
journal={arXiv preprint arXiv:2604.09450}
}
